



Local open LLMs for coding and public-sector use: the right model depends on the task and the hardware
The best local language model is not the one with the most impressive benchmark screenshot. For a developer, a university lab, a municipality or a ministry, the real question is different: which model can run reliably on available hardware, with acceptable latency, predictable cost, strong privacy and enough transparency to be trusted in production?
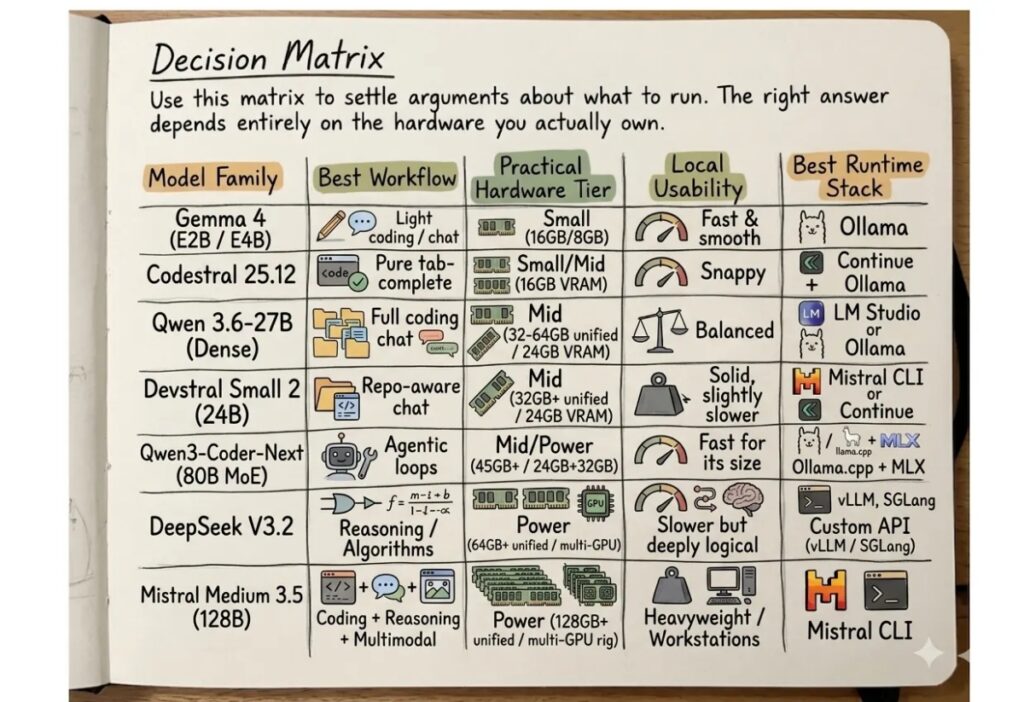
This is why the answer is not one model. It is a deployment strategy. A coding assistant for instant completion inside an editor needs a different model from a code-review agent that reads a repository, runs tests and proposes changes. A public-sector assistant that searches legislation, circulars, procurement records and administrative procedures needs a different architecture again. Local AI becomes useful when it is treated as infrastructure, not as a demo.
Coding assistants: fast completion, strong chat and agentic workflows
For software development, the most relevant open or open-weight families today are Qwen3-Coder, Devstral and StarCoder2, with smaller models used for low-latency completion. Qwen3-Coder is a strong choice for repository-scale work, tool use and coding agents. It is useful when the model must inspect files, reason over a codebase, propose patches, generate tests and iterate after failures. The 30B-A3B variant is particularly interesting for local use because it activates only a smaller part of the full model per token, which makes it more practical than a similarly sized dense model.
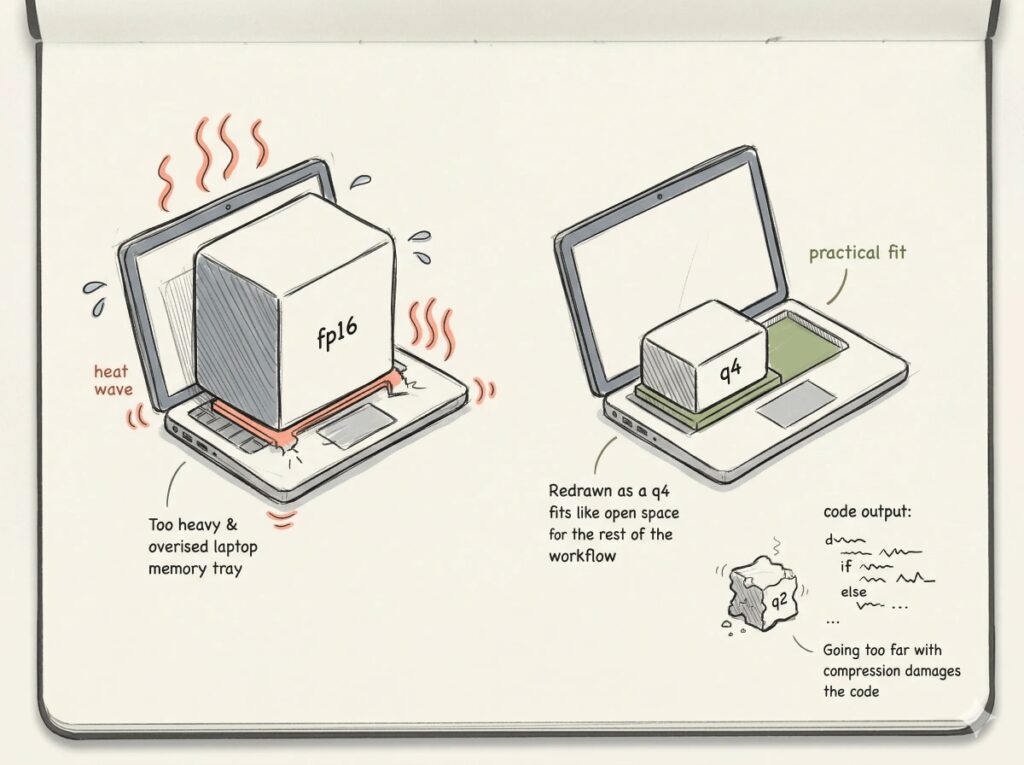
Devstral is another strong option for real software engineering rather than isolated code generation. It is designed for agentic software tasks: understanding a project, identifying bugs, proposing edits and working with scaffolds that connect the model to tests and code repositories. For public-interest software teams, it is useful for test generation, documentation, code review and controlled internal development workflows.
StarCoder2 remains important for a different reason: transparency. It comes from the BigCode ecosystem and is designed as an open code model family with visible attention to data governance and responsible use. It is not always the strongest model for complex reasoning, but it is highly relevant for education, universities, civic technology labs and public-sector training environments where provenance and reproducibility matter.
The practical lesson is simple: do not use the largest model for every task. For tab completion, a small model between 3B and 7B parameters is often better because latency matters more than deep reasoning. For architecture discussions, debugging, migration plans, test design and multi-file edits, a larger 24B to 32B model is more appropriate. A good coding setup therefore uses at least two models: one small and fast for completion, one larger and more capable for chat and agentic workflows.
Public-sector assistants: transparency matters more than novelty
In the public sector, the evaluation criteria change. Raw coding performance is not enough. Public administrations need transparency, auditability, European legal compatibility, data protection, multilingual capability and a clear distinction between open weights and fully open models. Open-weight models allow local deployment and adaptation. Fully open models go further by publishing more of the training process, data documentation, code and intermediate artifacts. For public services, this difference is not academic. It affects accountability.
OLMo is therefore highly relevant. It is one of the strongest examples of a fully open model family, useful for research, public-interest AI and auditable deployments. Apertus is equally important from a European perspective: a fully open, multilingual model designed around transparency and public-good principles. For Greece and other smaller-language countries, this is a strategic direction. Public services should not rely only on generic foreign cloud models. They should build controlled RAG systems over national legal, administrative and cultural data.
For low-risk services, smaller models such as SmolLM2 are often more appropriate than large models. A municipality does not need a 70B model to classify citizen requests, summarize a short document or route a question to the right department. Many public-sector tasks are better solved through retrieval, rules, classification, structured workflows and human review. Large models should be reserved for tasks where reasoning over complex text genuinely matters.
Hardware tiers that actually work
The first tier is a normal laptop or desktop with 16 to 32 GB of memory. This tier can run small 1.7B to 7B models in quantized form. It is suitable for training, experimentation, lightweight coding help and basic local assistants. It is not suitable for large repositories, long-context workflows or shared public-sector services.
The second tier is a developer workstation with 64 to 128 GB of system RAM and a GPU with 16 to 24 GB of VRAM, such as an RTX 4090-class card. This is the practical sweet spot for many teams. It can run 15B to 30B models in 4-bit or 5-bit quantization, provided context length is controlled. This tier is suitable for software teams, research groups, small public bodies and municipalities that want local coding support or controlled internal assistants.
The third tier is a professional workstation or departmental server with 48 GB of VRAM, such as an RTX 6000 Ada or L40S-class GPU, or a high-memory unified-memory workstation. This is where larger models, longer context windows, better retrieval pipelines and multiple users become realistic. It is suitable for regions, ministries, universities and public-sector innovation labs.
The fourth tier is a shared sovereign AI node: 2 to 4 professional 48 GB GPUs, 256 to 512 GB of RAM, fast NVMe storage, vLLM or llama.cpp for serving, LiteLLM as an OpenAI-compatible gateway, Keycloak for identity management, OpenSearch or PostgreSQL with vector search for RAG, and full audit logging. This is the appropriate architecture for national public AI infrastructure.
Recommended public strategy
A rational public strategy should use three layers. First, Qwen3-Coder or Devstral for coding, internal developer tools, test generation and secure code review. Second, OLMo and Apertus for public-sector knowledge assistants where transparency, multilingualism and institutional control matter. Third, smaller models such as SmolLM2 and StarCoder2 for low-cost deployments, education, routing, classification and local experimentation.
All public deployments should follow strict rules. Any answer about rights, taxes, benefits, permits, procurement or administrative procedures must be retrieval-grounded and cite the relevant source internally. There must be human final responsibility, model registries, Model Cards, Datasheets, audit logs, error reporting, bias evaluation where relevant and the ability to replace one model with another without rewriting the whole application.
Local open LLMs are not a magic shortcut. They are a way to reduce dependency, protect sensitive data, build domestic capacity and turn AI from a rented black box into public digital infrastructure. Used well, they can support both better software development and a more transparent, capable and democratic state.
Article sources:
- Qwen, Qwen3-Coder: The Qwen3-Coder family documents powerful open models for coding tasks, software agents, long-context workflows and local development, with available versions such as Qwen3-Coder-30B-A3B and Qwen3-Coder-Next: https://github.com/QwenLM/Qwen3-Coder and https://huggingface.co/Qwen/Qwen3-Coder-Next.
- Mistral AI, Devstral: Devstral is a model for agentic software engineering, released under Apache 2.0 and designed for real repository-level tasks, debugging and software testing: https://mistral.ai/news/devstral/.
- BigCode, StarCoder2: StarCoder2 is a family of open code models in 3B, 7B and 15B sizes, trained on a large multilingual code corpus and useful for code completion, education and more transparent deployments: https://github.com/bigcode-project/starcoder2 and https://huggingface.co/docs/transformers/en/model_doc/starcoder2.
- Allen Institute for AI, OLMo: OLMo is one of the most important examples of a fully open approach to language models, with emphasis on publishing weights, code, data and documentation, making it suitable as a model for publicly auditable AI: https://allenai.org/olmo.
- ETH Zurich, EPFL and CSCS, Apertus: Apertus is a European fully open, transparent and multilingual LLM, available in 8B and 70B parameter versions, with particular importance for public-sector and multilingual applications: https://ethz.ch/en/news-and-events/eth-news/news/2025/09/press-release-apertus-a-fully-open-transparent-multilingual-language-model.html.
- Hugging Face, SmolLM2: SmolLM2 demonstrates the practical value of small 135M, 360M and 1.7B models for on-device and low-cost uses, such as classification, routing and lightweight assistant tools: https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B.
- llama.cpp, Ollama, vLLM and LiteLLM: The open stack for local model execution and serving enables use across a wide range of hardware, OpenAI-compatible APIs, unified access gateways and model replacement without vendor lock-in: https://github.com/ggml-org/llama.cpp, https://docs.ollama.com/api/openai-compatibility, https://docs.vllm.ai/en/latest/serving/online_serving/openai_compatible_server/, https://docs.litellm.ai/docs/.
- NVIDIA and the European Commission, hardware and regulatory framework: The RTX 4090, RTX 6000 Ada and L40S specifications document the main 24GB and 48GB GPU categories for local LLMs, while the AI Act defines the risk-based logic that must be considered in public-sector AI applications: https://www.nvidia.com/en-eu/geforce/graphics-cards/40-series/rtx-4090/, https://www.nvidia.com/en-us/products/workstations/rtx-6000/, https://www.nvidia.com/en-eu/data-center/l40s/, https://digital-strategy.ec.europa.eu/en/policies/regulatory-framework-ai.
- Apple, Mac Studio with M3 Ultra and M4 Max: Apple documents Mac Studio configurations with M3 Ultra and M4 Max, high-bandwidth unified memory and technical specifications relevant to local LLM workloads, making it a strong workstation option for developers, research teams and public-sector AI labs that need large shared memory without a separate discrete GPU stack: https://www.apple.com/mac-studio/specs/ and https://www.apple.com/mac-studio/.
- AMD, Ryzen AI Max+ and AMD Instinct MI300 Series: AMD documents two relevant open local AI hardware paths: Ryzen AI Max+ systems with up to 128GB unified memory for workstation or small-cluster local LLM inference, and AMD Instinct MI300 accelerators for datacenter-class AI and HPC workloads with high memory density and bandwidth: https://www.amd.com/en/blogs/2025/amd-ryzen-ai-max-upgraded-run-up-to-128-billion-parameter-llms-lm-studio.html, https://www.amd.com/en/developer/resources/technical-articles/2026/how-to-run-a-one-trillion-parameter-llm-locally-an-amd.html and https://www.amd.com/en/products/accelerators/instinct/mi300.html.