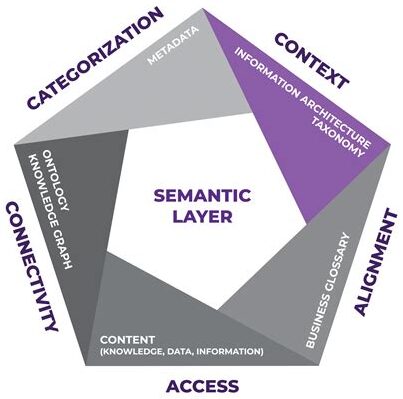



Semantica as a Knowledge Layer for Local Open-Source AI Models
Beyond the model: the need for accountable knowledge systems
The debate on local open-source AI models has entered a more mature phase. The central question is no longer whether a smaller open model can answer questions, summarize documents or assist with writing. The real question is whether it can operate with institutional reliability, transparency, auditability and a clear connection between every answer and the evidence that supports it.
This is where Semantica becomes important. It is not just another tool around large language models. It can operate as a knowledge, context and accountability layer between an organization’s data and the local AI model used for search, analysis and answer generation. This is especially important for public authorities, universities, research centres, municipalities, hospitals, small and medium-sized enterprises and organizations that do not want their documents and internal knowledge to become raw material for closed commercial platforms.
Local open models become powerful when they are connected to well-organized knowledge. If a model answers only from what it learned during training, it remains vulnerable to errors, omissions and plausible but incorrect statements. If, however, it is connected to structured repositories, knowledge graphs, provenance records, rules and conflict detection mechanisms, the same model can become far more useful, even if it is smaller than a frontier commercial model.
This is also a political and institutional issue. A local model is not automatically trustworthy just because it runs on local infrastructure. It becomes trustworthy when it is embedded in a system that can show where information came from, how relationships were extracted, which rules were applied, where sources disagree and why a specific answer was produced. Semantica can provide precisely this layer.
Knowledge graphs instead of isolated text chunks
Traditional RAG retrieves relevant text chunks and passes them to a language model as context. This is useful, but often insufficient. In legal, administrative, scientific and regulatory environments, knowledge is not just text. It consists of people, institutions, rules, dates, decisions, obligations, exceptions, dependencies and time-bound validity. Semantica makes it possible to transform documents, web pages, reports and databases into knowledge graphs, structured representations of entities and relationships.
This matters greatly for local AI systems. A public or research-oriented stack built around GlossAPI and open models can gather Greek language corpora, legislation, administrative procedures, technical manuals, educational material and research publications. Semantica can then identify entities, extract relationships, resolve duplicates, organize terminology into ontologies and allow the model to answer not only through semantic similarity, but also through the actual relationships found in the knowledge base.
In this architecture, the local model does not need to guess what is true. Semantica can provide structured context: which source says what, which relationship connects two concepts, which rule is currently valid, which sources conflict and which conclusions follow from explicit reasoning rules. This is the shift from chatting with a model to using an accountable organizational memory.
For a public administration use case, this distinction is decisive. A simple RAG system may retrieve a paragraph from a procedure manual. A graph-based system can connect the citizen’s question to the relevant institution, legal basis, required documents, exceptions, deadlines and prior decisions. The answer becomes more precise, more explainable and easier to review by a human official.
Provenance, reasoning and human oversight
The strongest value of Semantica for local open models is not only accuracy. It is accountability. In public-sector, legal, healthcare, research and education settings, it is not enough for an answer to sound correct. It must be inspectable. One must be able to know which document supports a claim, which extraction method produced a fact, which ontology rules were applied, which reasoning path led to a conclusion and which uncertainty remains.
Semantica introduces this logic directly into the AI stack. Provenance, decision intelligence, conflict detection and reasoning traces can become part of the infrastructure rather than after-the-fact documentation. This fits well with the principle that AI in public administration should assist humans, not replace institutional responsibility. The model may summarize, compare, propose and explain. The final responsibility remains with the human professional and the public institution.
For example, in a citizen-service assistant, the system should not give general answers about a permit, a benefit or an administrative procedure. It should retrieve the relevant procedure, required documents, exceptions, dates and institutional sources from the knowledge graph. In a university, it can support search across study regulations, research calls, internal policies and technical documentation. In a hospital or social care setting, it can only be used within carefully governed workflows, with human review, strict access controls and documented evidence trails.
This is also why smaller local models can be strategically useful. A well-governed local model connected to a reliable knowledge graph may be more appropriate than a larger remote model that cannot expose its evidence path, cannot be fully audited and creates dependency on an external provider. The key performance issue is not only model size. It is the quality of the knowledge environment around the model.
A Greek public-interest architecture for AI
Semantica is particularly relevant for the Greek language and for public digital infrastructure in Greece. Most commercial AI systems are not designed around Greek legal, administrative, educational and cultural contexts. GlossAPI can act as a pipeline for Greek AI-ready data, while Semantica can transform those data into structured, auditable and semantically organized knowledge.
This opens a practical path toward a public AI infrastructure that does not depend on exporting sensitive data to closed clouds. Such an infrastructure can use local open models, local embeddings, open vector databases, knowledge graphs, domain ontologies, provenance standards and auditable reasoning. It can serve ministries, municipalities, universities, schools, research centres and small businesses. It can also strengthen the Greek language as a living digital infrastructure rather than leaving it dependent on foreign models trained primarily for other languages and markets.
The most important point is that Semantica does not replace local AI models. It makes them more useful. It gives them memory that can be queried, sources that can be checked, relationships that can be traversed and decisions that can be audited. In this sense, it can help transform local open-source AI from a low-cost alternative into a serious institutional capability.
For Greece and Europe, this is the right direction. AI should not be reduced to subscriptions to remote black boxes. It should become a democratic knowledge infrastructure, locally controlled, open where possible, auditable where necessary and useful for public purpose. Semantica can be one of the building blocks of that transition, especially when combined with GlossAPI, open models, sovereign infrastructure and a clear commitment to public accountability.
Article sources:
- Semantica, Core Concepts: The documentation explains Semantica as a context and accountability layer for AI stacks, combining knowledge graphs, GraphRAG, ontologies, provenance, reasoning, temporal intelligence and conflict detection: https://docs.getsemantica.ai/concepts/,
- Semantica, PyPI project page: The PyPI page verifies that Semantica is available as a Python package under the MIT License, supports Python 3.8 and later, and includes optional integrations for local and hosted models, graph stores and vector stores: https://pypi.org/project/semantica/,
- GlossAPI, “Τοπικά μοντέλα ΤΝ ανοιχτού λογισμικού”: The article explains why local open-source AI models are a safer, cheaper and more democratic option for the public sector, businesses and education, especially when combined with well-organized knowledge retrieval: https://blog.glossapi.gr/τοπικά-μοντέλα-τν-ανοιχτού-λογισμικο/,
- Microsoft GraphRAG documentation: The documentation presents GraphRAG as a structured retrieval approach that uses knowledge graphs instead of relying only on plain text snippets, which is crucial for grounded answers over complex knowledge bases: https://microsoft.github.io/graphrag/,
- W3C, PROV-O: The PROV Ontology: The W3C PROV-O standard provides a formal way to represent provenance and data lineage, which is essential for auditable AI systems in public and regulated environments: https://www.w3.org/TR/prov-o/,
- Ollama, Embeddings documentation: The documentation shows how local embeddings can support semantic search, retrieval and RAG pipelines, making them a practical component of low-cost local AI infrastructure: https://docs.ollama.com/capabilities/embeddings.