



Τοπικά ανοικτά LLMs για προγραμματισμό και δημόσιο τομέα: ποια μοντέλα; σε ποιο υλικό; για ποια χρήση;
Η συζήτηση για τα τοπικά γλωσσικά μοντέλα δεν πρέπει να ξεκινά από το ερώτημα «ποιο μοντέλο έχει το υψηλότερο σκορ». Για έναν προγραμματιστή, έναν δήμο, ένα υπουργείο ή μια δημόσια υποδομή, το σωστό ερώτημα είναι πιο πρακτικό: ποιο μοντέλο μπορεί να τρέξει σταθερά, με αποδεκτό χρόνο απόκρισης, με ελεγχόμενο κόστος, με προστασία δεδομένων και με δυνατότητα ελέγχου από την ίδια την κοινότητα που το χρησιμοποιεί;
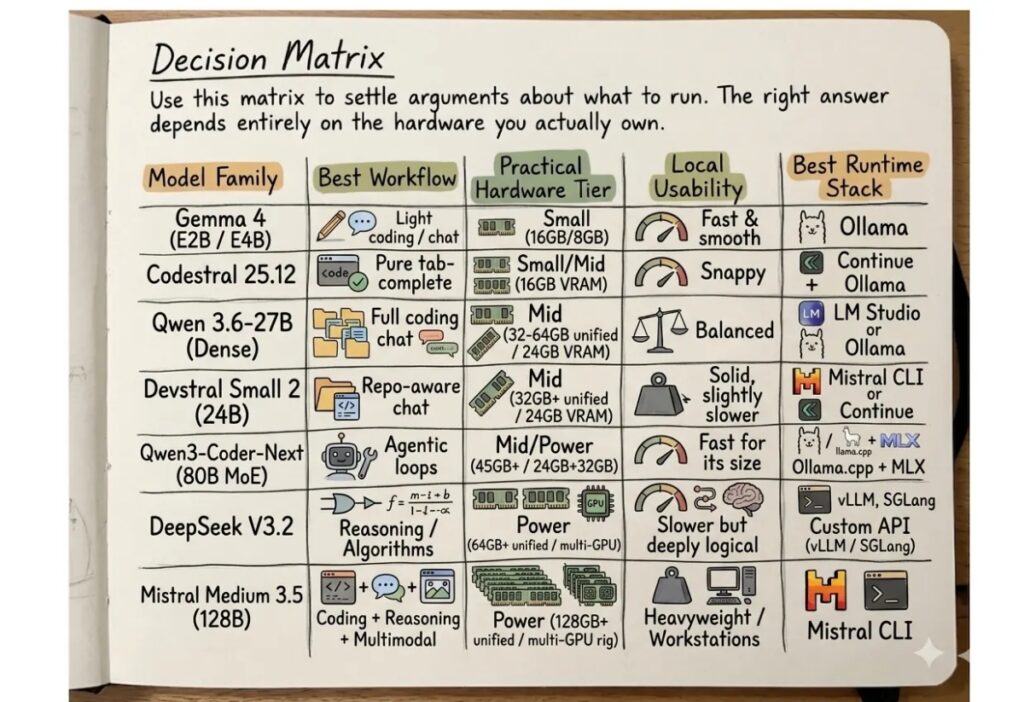
Η απάντηση δεν είναι ένα μοντέλο. Είναι μια στοίβα επιλογών. Άλλο μοντέλο χρειάζεται ο προγραμματιστής για γρήγορη συμπλήρωση κώδικα μέσα στο περιβάλλον ανάπτυξης, άλλο μοντέλο χρειάζεται μια ομάδα λογισμικού για ανάλυση αποθετηρίου και διόρθωση σφαλμάτων, άλλο μοντέλο χρειάζεται ένας δημόσιος φορέας για αναζήτηση σε ΦΕΚ, αποφάσεις, εγκυκλίους και διαδικασίες. Η τοπική ΤΝ έχει νόημα όταν σχεδιάζεται ως δημόσια και παραγωγική υποδομή, όχι ως εντυπωσιακή επίδειξη.
Τα καταλληλότερα μοντέλα για βοηθούς προγραμματισμού
Για εργασίες προγραμματισμού, οι πιο χρήσιμες οικογένειες σήμερα είναι τα Qwen3-Coder, Devstral, StarCoder2 και, σε ειδικές περιπτώσεις, μικρότερα μοντέλα για γρήγορη συμπλήρωση. Το Qwen3-Coder είναι ισχυρή επιλογή για σύνθετες εργασίες κώδικα, ανάλυση μεγαλύτερων αποθετηρίων, χρήση εργαλείων και αυτοματοποιημένες ροές όπου το μοντέλο πρέπει να διαβάζει αρχεία, να προτείνει αλλαγές, να εκτελεί δοκιμές και να επανέρχεται με διορθώσεις. Η έκδοση Qwen3-Coder-30B-A3B είναι ιδιαίτερα ενδιαφέρουσα για σταθμούς εργασίας με ισχυρή κάρτα γραφικών, επειδή ενεργοποιεί μικρότερο μέρος των παραμέτρων ανά βήμα και άρα μπορεί να είναι αποδοτικότερη από ένα αντίστοιχο πλήρως πυκνό μοντέλο.
Το Devstral είναι επίσης πολύ ισχυρή επιλογή για μηχανικούς λογισμικού. Δεν είναι απλώς μοντέλο που γράφει συναρτήσεις. Έχει σχεδιαστεί για εργασίες τύπου πράκτορα λογισμικού, όπου χρειάζεται να κατανοήσει το πλαίσιο ενός έργου, να εντοπίσει λάθη, να προτείνει αλλαγές και να συνεργαστεί με εργαλεία όπως συστήματα δοκιμών ή αποθετήρια κώδικα. Για ομάδες που αναπτύσσουν δημόσιο λογισμικό, μπορεί να χρησιμοποιηθεί σε ελεγχόμενο περιβάλλον για δημιουργία δοκιμών, ανασκόπηση αλλαγών, τεκμηρίωση και εντοπισμό πιθανών λαθών ασφαλείας.
Το StarCoder2 παραμένει σημαντικό γιατί προέρχεται από μια παράδοση πιο διαφανούς ανάπτυξης μοντέλων κώδικα. Είναι κατάλληλο για πιο ελαφριές εγκαταστάσεις, για συμπλήρωση κώδικα, εκπαιδευτική χρήση, εργαστήρια, πανεπιστήμια και ομάδες που θέλουν ένα μοντέλο με σαφέστερη σχέση με τα δεδομένα εκπαίδευσης και με πιο ελεγχόμενη αδειοδότηση. Δεν είναι πάντα το ισχυρότερο σε σύνθετο συλλογισμό, αλλά είναι χρήσιμο για δημόσιες και εκπαιδευτικές εγκαταστάσεις όπου η διαφάνεια της προέλευσης έχει μεγάλη αξία.
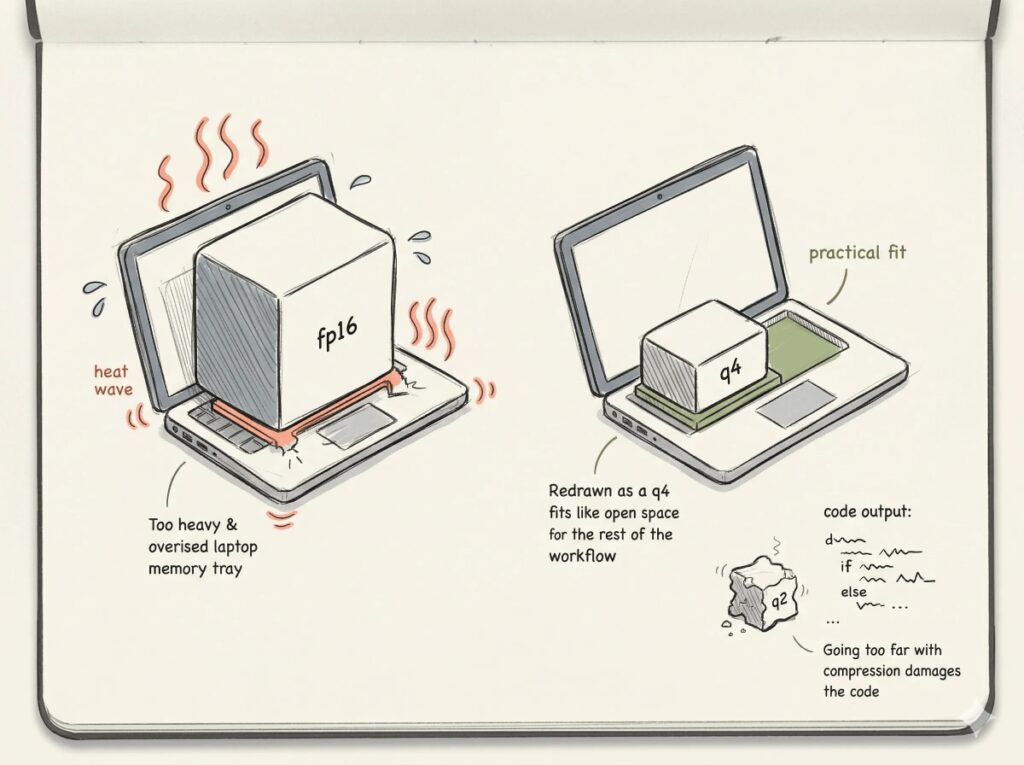
Για καθαρή αυτόματη συμπλήρωση, η καλύτερη πρακτική είναι να μη χρησιμοποιείται το μεγαλύτερο μοντέλο. Ένα μικρότερο μοντέλο 3B έως 7B, σε συμπιεσμένη μορφή, μπορεί να δώσει πολύ καλύτερη εμπειρία χρήστη από ένα 30B μοντέλο που καθυστερεί. Ο προγραμματιστής χρειάζεται απάντηση σε κλάσματα δευτερολέπτου όταν γράφει κώδικα. Για συζήτηση αρχιτεκτονικής, ανάλυση σφαλμάτων και παραγωγή τεκμηρίωσης μπορεί να περιμένει περισσότερο. Άρα η σωστή αρχιτεκτονική έχει δύο μοντέλα: μικρό για συμπλήρωση, μεγαλύτερο για συνομιλία και πράκτορες.
Τα καταλληλότερα μοντέλα για τον δημόσιο τομέα
Στον δημόσιο τομέα, το κριτήριο αλλάζει. Δεν αρκεί η απόδοση στον κώδικα. Προέχουν η διαφάνεια, η δυνατότητα ελέγχου, η γλωσσική κάλυψη, η συμβατότητα με ευρωπαϊκό δίκαιο, η προστασία προσωπικών δεδομένων και η τεκμηρίωση. Εδώ πρέπει να διακρίνουμε τα «ανοικτά βάρη» από τα «πλήρως ανοικτά» μοντέλα. Ένα μοντέλο ανοικτών βαρών επιτρέπει τοπική εκτέλεση και προσαρμογή. Ένα πλήρως ανοικτό μοντέλο δημοσιεύει περισσότερα στοιχεία για τα δεδομένα, τη μεθοδολογία, τον κώδικα και τα ενδιάμεσα στάδια εκπαίδευσης. Για δημόσιες εφαρμογές, η δεύτερη κατηγορία έχει πολύ μεγαλύτερη θεσμική αξία.
Το OLMo είναι από τις πιο σημαντικές επιλογές για δημόσια ελεγχόμενη ΤΝ, επειδή δίνει βάρος στην πλήρη ανοικτότητα. Είναι κατάλληλο για ερευνητικές και δημόσιες εφαρμογές όπου χρειάζεται δυνατότητα ελέγχου της διαδικασίας ανάπτυξης. Το Apertus είναι επίσης κρίσιμο ευρωπαϊκό παράδειγμα: πλήρως ανοικτό, πολυγλωσσικό και σχεδιασμένο με λογική δημόσιου συμφέροντος. Για την Ελλάδα, τέτοιες προσεγγίσεις είναι ιδιαίτερα χρήσιμες ως βάση για ελληνικά fine-tunes και για RAG συστήματα πάνω σε ΦΕΚ, Διαύγεια, ΜΙΤΟΣ, ΚΗΜΔΗΣ, αποφάσεις και διοικητικές διαδικασίες.
Για χαμηλού κόστους υπηρεσίες πρώτης γραμμής, όπως ταξινόμηση αιτημάτων, περίληψη μικρών κειμένων, δρομολόγηση ερωτήσεων και τοπικά kiosks, μικρά μοντέλα όπως το SmolLM2 είναι πιο λογικά από μεγάλα μοντέλα. Η δημόσια διοίκηση δεν χρειάζεται παντού ένα τεράστιο LLM. Χρειάζεται σωστή αντιστοίχιση μοντέλου και εργασίας. Πολλά προβλήματα λύνονται με αναζήτηση, κανόνες, ταξινόμηση, RAG και ανθρώπινη επικύρωση.
Υλικό: τέσσερις πρακτικές κατηγορίες
Η πρώτη κατηγορία είναι ο απλός φορητός ή επιτραπέζιος υπολογιστής με 16 έως 32 GB μνήμης. Εδώ τρέχουν μικρά μοντέλα 1.7B έως 7B σε συμπιεσμένη μορφή. Είναι κατάλληλα για εκπαίδευση, δοκιμές, βασική συμπλήρωση κώδικα και ελαφριά συνομιλία. Δεν είναι κατάλληλα για ανάλυση ολόκληρων αποθετηρίων ή βαριά δημόσια χρήση.
Η δεύτερη κατηγορία είναι ο σταθμός εργασίας με 64 έως 128 GB RAM και κάρτα γραφικών 16 έως 24 GB VRAM, όπως μια RTX 4090. Εδώ μπορεί να λειτουργήσει ικανοποιητικά ένα 15B έως 30B μοντέλο σε 4-bit ή 5-bit συμπίεση, με προσοχή στο μέγεθος του ιστορικού συνομιλίας. Αυτή είναι η πιο ρεαλιστική κατηγορία για ομάδες ανάπτυξης λογισμικού, πανεπιστημιακά εργαστήρια, δήμους και μικρούς φορείς.
Η τρίτη κατηγορία είναι ο επαγγελματικός σταθμός με 48 GB VRAM, όπως RTX 6000 Ada ή L40S, ή αντίστοιχη ενιαία μνήμη σε Apple Silicon. Εδώ αρχίζει η σοβαρή χρήση μεγαλύτερων μοντέλων, καλύτερου RAG, μεγαλύτερων συμφραζομένων και περισσότερων ταυτόχρονων χρηστών. Είναι κατάλληλη για περιφέρειες, μεγάλα πανεπιστημιακά εργαστήρια και υπουργικές ομάδες καινοτομίας.
Η τέταρτη κατηγορία είναι ο κοινός δημόσιος κόμβος ΤΝ: 2 έως 4 επαγγελματικές GPUs των 48 GB, 256 έως 512 GB RAM, γρήγορο NVMe αποθηκευτικό σύστημα, vLLM ή llama.cpp για εκτέλεση, LiteLLM ως πύλη συμβατή με OpenAI API, Keycloak για ταυτοποίηση, OpenSearch ή PostgreSQL/pgvector για RAG και πλήρη καταγραφή χρήσης. Αυτή είναι η σωστή αρχιτεκτονική για εθνική δημόσια υποδομή ΤΝ.
Η πρόταση πολιτικής
Για την Ελλάδα, η πιο ορθολογική επιλογή είναι τριπλή. Πρώτον, Qwen3-Coder ή Devstral για προγραμματισμό, εσωτερικά εργαλεία ανάπτυξης και ανασκόπηση κώδικα. Δεύτερον, OLMo και Apertus για δημόσιες εφαρμογές που απαιτούν διαφάνεια, πολυγλωσσία και θεσμικό έλεγχο. Τρίτον, μικρά μοντέλα όπως SmolLM2 και StarCoder2 για οικονομικές εγκαταστάσεις, εκπαίδευση και υπηρεσίες χαμηλού κινδύνου.
Όλα αυτά πρέπει να λειτουργούν με αυστηρούς κανόνες: RAG για κάθε διοικητική απάντηση, παραπομπή σε πηγή, ανθρώπινη τελική ευθύνη, μητρώο μοντέλων, Model Cards, Datasheets, καταγραφή κλήσεων, αξιολόγηση σφαλμάτων και δυνατότητα αντικατάστασης μοντέλου χωρίς αλλαγή εφαρμογής. Η ΤΝ στο δημόσιο δεν πρέπει να είναι μαύρο κουτί. Πρέπει να είναι δημόσια υποδομή γνώσης, ελέγχου και παραγωγικής αυτονομίας.
Πηγές άρθρου:
- Qwen, Qwen3-Coder: Η οικογένεια Qwen3-Coder τεκμηριώνει ισχυρά ανοικτά μοντέλα για εργασίες κώδικα, πράκτορες λογισμικού, μεγάλα συμφραζόμενα και τοπική ανάπτυξη, με διαθέσιμες εκδόσεις όπως Qwen3-Coder-30B-A3B και Qwen3-Coder-Next: https://github.com/QwenLM/Qwen3-Coder και https://huggingface.co/Qwen/Qwen3-Coder-Next.
- Mistral AI, Devstral: Το Devstral είναι μοντέλο για agentic software engineering, διατίθεται με Apache 2.0 και έχει σχεδιαστεί για πραγματικές εργασίες αποθετηρίων, debugging και δοκιμών λογισμικού: https://mistral.ai/news/devstral/.
- BigCode, StarCoder2: Το StarCoder2 είναι οικογένεια ανοικτών μοντέλων κώδικα 3B, 7B και 15B, εκπαιδευμένων σε μεγάλο πολυγλωσσικό σώμα κώδικα, χρήσιμων για συμπλήρωση κώδικα, εκπαίδευση και διαφανέστερες εγκαταστάσεις: https://github.com/bigcode-project/starcoder2 και https://huggingface.co/docs/transformers/en/model_doc/starcoder2.
- Allen Institute for AI, OLMo: Το OLMo είναι από τα σημαντικότερα παραδείγματα πλήρως ανοικτής προσέγγισης σε γλωσσικά μοντέλα, με έμφαση στη δημοσίευση βαρών, κώδικα, δεδομένων και τεκμηρίωσης, άρα κατάλληλο ως πρότυπο δημόσια ελέγξιμης ΤΝ: https://allenai.org/olmo.
- ETH Zurich, EPFL και CSCS, Apertus: Το Apertus είναι ευρωπαϊκό πλήρως ανοικτό, διαφανές και πολυγλωσσικό LLM, διαθέσιμο σε 8B και 70B παραμέτρους, με ιδιαίτερη σημασία για δημόσιες και πολυγλωσσικές εφαρμογές: https://ethz.ch/en/news-and-events/eth-news/news/2025/09/press-release-apertus-a-fully-open-transparent-multilingual-language-model.html.
- Hugging Face, SmolLM2: Το SmolLM2 τεκμηριώνει την πρακτική αξία μικρών μοντέλων 135M, 360M και 1.7B για on-device και χαμηλού κόστους χρήσεις, όπως ταξινόμηση, δρομολόγηση και ελαφριά βοηθητικά εργαλεία: https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B.
- llama.cpp, Ollama, vLLM και LiteLLM: Η ανοικτή στοίβα τοπικής εκτέλεσης και εξυπηρέτησης μοντέλων επιτρέπει χρήση σε ευρύ φάσμα υλικού, OpenAI-compatible APIs, ενιαίες πύλες πρόσβασης και αντικατάσταση μοντέλων χωρίς κλείδωμα σε έναν προμηθευτή: https://github.com/ggml-org/llama.cpp, https://docs.ollama.com/api/openai-compatibility, https://docs.vllm.ai/en/latest/serving/online_serving/openai_compatible_server/, https://docs.litellm.ai/docs/.
- NVIDIA και European Commission, υλικό και κανονιστικό πλαίσιο: Οι προδιαγραφές RTX 4090, RTX 6000 Ada και L40S τεκμηριώνουν τις βασικές κατηγορίες GPU 24GB και 48GB για τοπικά LLMs, ενώ το AI Act ορίζει τη λογική ρίσκου που πρέπει να λαμβάνεται υπόψη σε δημόσιες εφαρμογές ΤΝ: https://www.nvidia.com/en-eu/geforce/graphics-cards/40-series/rtx-4090/, https://www.nvidia.com/en-us/products/workstations/rtx-6000/, https://www.nvidia.com/en-eu/data-center/l40s/, https://digital-strategy.ec.europa.eu/en/policies/regulatory-framework-ai.
- Apple, Mac Studio με M3 Ultra και M4 Max: Η Apple τεκμηριώνει διαμορφώσεις Mac Studio με M3 Ultra και M4 Max, ενοποιημένη μνήμη υψηλού εύρους ζώνης και τεχνικές προδιαγραφές σχετικές με τοπικά φορτία LLM, καθιστώντας το Mac Studio ισχυρή επιλογή σταθμού εργασίας για προγραμματιστές, ερευνητικές ομάδες και εργαστήρια δημόσιας ΤΝ που χρειάζονται μεγάλη κοινόχρηστη μνήμη χωρίς ξεχωριστή στοίβα διακριτής GPU: https://www.apple.com/mac-studio/specs/ και https://www.apple.com/mac-studio/.
- AMD, Ryzen AI Max+ και AMD Instinct MI300 Series: Η AMD τεκμηριώνει δύο σχετικές διαδρομές υλικού για ανοικτή τοπική ΤΝ: συστήματα Ryzen AI Max+ με έως 128GB ενοποιημένη μνήμη για τοπικό inference LLM σε σταθμούς εργασίας ή μικρά clusters, και επιταχυντές AMD Instinct MI300 για υποδομές datacenter με υψηλή πυκνότητα μνήμης και μεγάλο εύρος ζώνης για AI και HPC φορτία: https://www.amd.com/en/blogs/2025/amd-ryzen-ai-max-upgraded-run-up-to-128-billion-parameter-llms-lm-studio.html, https://www.amd.com/en/developer/resources/technical-articles/2026/how-to-run-a-one-trillion-parameter-llm-locally-an-amd.html και https://www.amd.com/en/products/accelerators/instinct/mi300.html.