



AI Factories or digital dependency?
Why the current AI infrastructure boom mainly enriches NVIDIA and other multinationals The global race to build “AI Factories” is being sold as the next great industrial transformation. Governments promise sovereign compute, strategic autonomy, new datacentres, thousands of jobs and a productivity revolution powered by artificial intelligence. Yet the political language of national capability often […]
Beyond single models: architecture as competitive advantage
The typical ML engineer follows a familiar workflow: choose an architecture, train, evaluate. This mindset leads to searching for a single model that solves the entire problem on its own. In practice, no single computational paradigm fully meets the demands of real-world applications, especially in the public sector and regulated environments. The solution is not […]

GlossAPI and the Swiss AI Initiative: a strategic investment in Greek as public digital infrastructure
An approval that changes the scale of ambition The approval of the proposal “Enhancing multilingual foundation models through lexicographic grounding: advancing GlossAPI for Apertus Greek language integration” by the Swiss AI Initiative is more than a welcome grant decision. It is a recognition that Greek should be treated as critical digital infrastructure in the age […]

When AI Solves Open Mathematical Problems
On February 28, 2026, Donald Knuth, professor emeritus at Stanford University and author of the landmark work The Art of Computer Programming, published a note titled “Claude’s Cycles” describing how Anthropic’s Claude Opus 4.6 model solved an open problem in combinatorial mathematics that he had been working on for weeks. The announcement marks a significant […]

AI Agents
Benefits and risks for the public and private sectors AI agents are not just better chatbots. They are systems that combine language models with tools, memory, retrieval, and the ability to execute multi step actions across software environments. That combination gives them real productive potential for both the Greek public sector and private firms, but […]

When AI Lies on Purpose: What Research Reveals
Beyond hallucination: a qualitative shift Public discussion about the shortcomings of large language models has long focused on so-called “hallucinations,” the generation of plausible but factually incorrect outputs resulting from statistical misprediction. However, a study published in September 2025 by OpenAI in collaboration with Apollo Research has documented something qualitatively different: models such as o3 […]
Local, Low-Cost Open Source AI Models: A Sovereign and Sustainable Alternative for the Public Sector and SMEs
From Hyperscale Cloud Dependence to Efficient Local Infrastructure Europe’s AI strategy is at a structural crossroads. Market concentration in AI compute and cloud infrastructure, as documented by the OECD, exposes public administrations and SMEs to systemic dependency risks. At the regulatory level, the EU AI Act establishes binding obligations for transparency, risk management, and accountability. […]
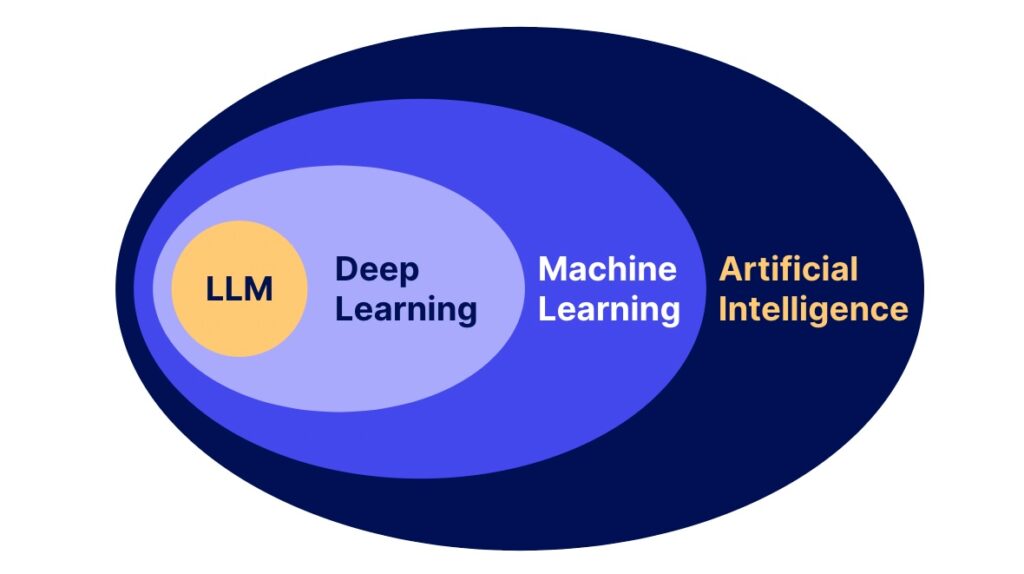
From LLMs that “talk” to systems that “understand”
Five inventions needed to ground AI in reality Large Language Models have achieved a remarkable feat: they compress a vast fraction of written human knowledge into a next-token prediction engine. Yet the very nature of this success exposes a structural gap. Language describes the world, but it is not the world. As a result, today’s […]

AGI Is Not Around the Corner
Why Artificial General Intelligence Remains a Distant Prospect Public discourse has increasingly conflated today’s generative AI systems with the imminent arrival of Artificial General Intelligence. The assumption that scaling large language models will naturally culminate in human-level cognition has become widespread. Yet, scientific evidence suggests a far more cautious assessment. Statistical Patterning Versus Understanding Large […]

This Is Not the AI We Were Promised
Scientific reasons why uncritical LLM adoption in government is unsafe Michael Wooldridge’s Royal Society lecture makes a crucial point for public policy: today’s large language models are not “reasoning minds” but probabilistic next-token predictors. They generate fluent text without an internal notion of truth, accountability, or epistemic humility. This design reality matters most in the […]
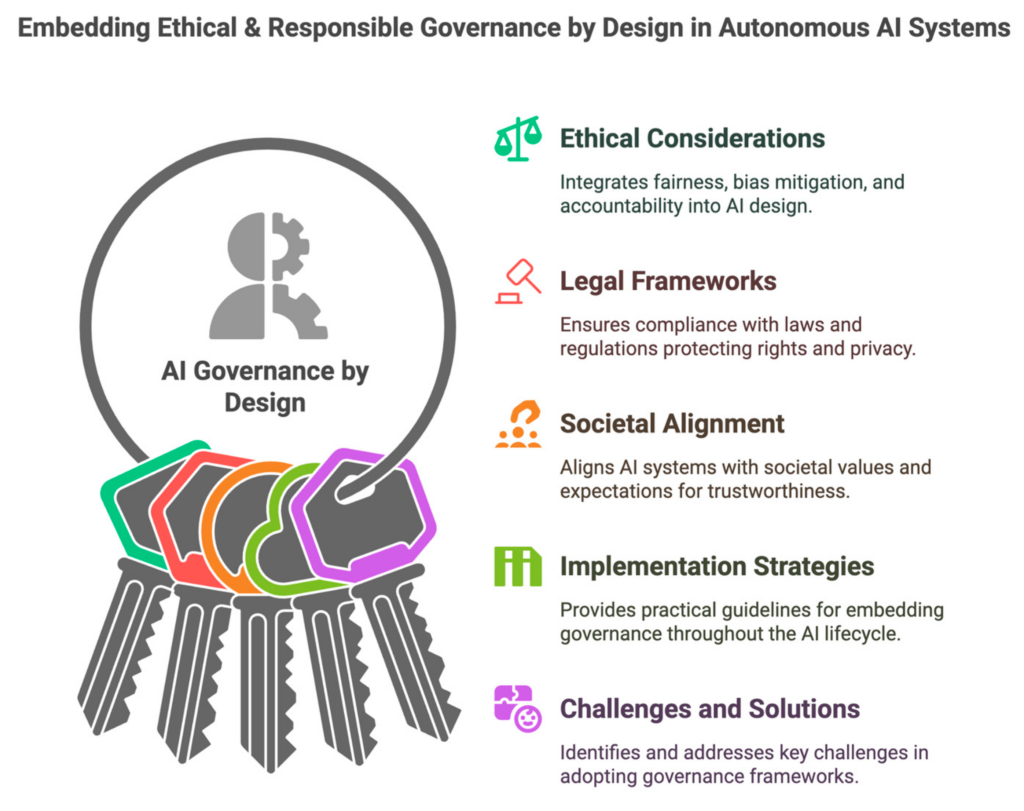
Artificial Intelligence and the Public Interest
Scientific Arguments Against Uncritical Deployment in the Public Sector Artificial Intelligence is frequently presented as a neutral instrument of modernization within public administration. Claims of efficiency and cost reduction dominate policy discourse. Yet a growing body of scientific research demonstrates that uncritical deployment of AI systems in public institutions poses structural risks to democratic governance, […]

Building an Open Greek Book Corpus from Openbook.gr
From Web Scraping to a Clean, Research-Ready Dataset At GlossAPI, our mission is to build open, high-quality Greek language datasets that support the Greek AI ecosystem. In this article, we present our latest dataset: a large-scale collection of Greek books sourced from Openbook.gr, processed and cleaned using the GlossAPI pipeline, and prepared for publication through […]