



Γιατί οι επενδύσεις τεχνητής νοημοσύνης καταλήγουν σε λίγες πολυεθνικές
Η δημόσια συζήτηση για τα λεγόμενα εργοστάσια τεχνητής νοημοσύνης(AI Factories) παρουσιάζεται συνήθως ως μια υπόσχεση τεχνολογικής προόδου, εθνικής ισχύος και οικονομικού μετασχηματισμού. Κυβερνήσεις, επενδυτικά ταμεία και μεγάλοι τεχνολογικοί όμιλοι μιλούν για νέα υπολογιστικά κέντρα, υπερυπολογιστές, χιλιάδες θέσεις εργασίας και ένα υποτιθέμενο άλμα παραγωγικότητας. Όμως όσο προχωρά η διεθνής εμπειρία, τόσο γίνεται πιο σαφές ότι πίσω […]
Πέρα από τα μεμονωμένα μοντέλα: η αρχιτεκτονική ως ανταγωνιστικό πλεονέκτημα
Συνήθως ο προγραμματιστής μηχανικής μάθησης ακολουθεί μια συγκεκριμένη ροή εργασίας: επιλέγει αρχιτεκτονική, εκπαιδεύει, αξιολογεί. Αυτή η λογική οδηγεί σε αναζήτηση ενός μοντέλου που θα λύσει ολόκληρο το πρόβλημα μόνο του. Στην πράξη, κανένα μεμονωμένο υπολογιστικό παράδειγμα δεν ανταποκρίνεται πλήρως στις απαιτήσεις πραγματικών εφαρμογών, ιδίως στον δημόσιο τομέα και σε ρυθμιζόμενα περιβάλλοντα. Η λύση δεν βρίσκεται […]

GlossAPI και Swiss AI Initiative: μια στρατηγική επένδυση για την ελληνική γλώσσα ως δημόσια ψηφιακή υποδομή
Η έγκριση που αλλάζει κατηγορία για το GlossAPI Η έγκριση της πρότασης «Enhancing multilingual foundation models through lexicographic grounding: advancing GlossAPI for Apertus Greek language integration» από το Swiss AI Initiative δεν είναι μια ακόμη επιτυχία χρηματοδότησης. Είναι μια έμπρακτη αναγνώριση ότι η ελληνική γλώσσα μπορεί και πρέπει να αντιμετωπίζεται ως κρίσιμη ψηφιακή υποδομή. Σύμφωνα […]

Όταν η ΤΝ λύνει ανοιχτά μαθηματικά προβλήματα
Στις 28 Φεβρουαρίου 2026, ο Donald Knuth, καθηγητής emeritus στο Πανεπιστήμιο Stanford και συγγραφέας του μνημειώδους The Art of Computer Programming, δημοσίευσε μια σημείωση με τίτλο “Claude’s Cycles” στην οποία περιγράφει πώς το μοντέλο Claude Opus 4.6 της Anthropic έλυσε ένα ανοιχτό πρόβλημα συνδυαστικής μαθηματικής πάνω στο οποίο εργαζόταν ο ίδιος εδώ και εβδομάδες. Η […]

Πράκτορες Τεχνητής Νοημοσύνης(ΤΝ)
Τα οφέλη και οι κίνδυνοι για Δημόσιο και επιχειρήσεις Οι πράκτορες(agents) ΤΝ δεν είναι απλώς πιο «έξυπνα chatbots». Είναι συστήματα που συνδυάζουν γλωσσικά μοντέλα με εργαλεία, μνήμη, αναζήτηση και δυνατότητα εκτέλεσης ενεργειών σε πολλαπλά βήματα. Αυτό τους καθιστά ιδιαίτερα χρήσιμους τόσο για τον δημόσιο όσο και για τον ιδιωτικό τομέα στην Ελλάδα, αλλά ακριβώς αυτή […]

Όταν η ΤΝ ψεύδεται εν γνώσει της: τι αποκαλύπτει έρευνα για την εξαπάτηση
Από την παραίσθηση στη στρατηγική απάτη Η δημόσια συζήτηση για τα σφάλματα των μεγάλων γλωσσικών μοντέλων επικεντρώνεται συνήθως στις λεγόμενες «παραισθήσεις», δηλαδή στην παραγωγή ψευδών πληροφοριών λόγω στατιστικών αστοχιών. Ωστόσο, πρόσφατη έρευνα που δημοσιεύθηκε τον Σεπτέμβριο 2025, σε συνεργασία της OpenAI με την Apollo Research, αποκάλυψε ένα ποιοτικά διαφορετικό φαινόμενο: μοντέλα όπως τα o3 και […]
Τοπικά μοντέλα ΤΝ ανοιχτού λογισμικού
Η ασφαλέστερη, φθηνότερη και πιο δημοκρατική επιλογή για Δημόσιο, επιχειρήσεις και εκπαίδευση Η συζήτηση για την Τεχνητή Νοημοσύνη στην Ευρώπη περνά σε πιο ώριμη φάση. Το κρίσιμο ερώτημα δεν είναι πλέον αν το Δημόσιο, οι επιχειρήσεις και τα εκπαιδευτικά ιδρύματα θα χρησιμοποιήσουν ΤΝ, αλλά με ποιους όρους θα τη χρησιμοποιήσουν. Θα στηριχθούν σε αδιαφανείς εμπορικές […]
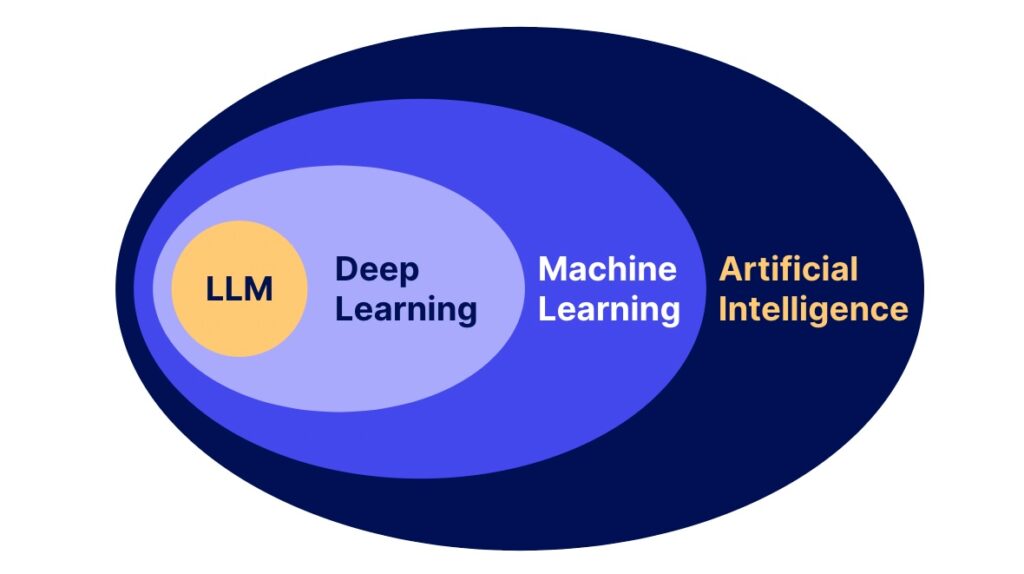
Από τα LLMs που «μιλούν» στα συστήματα που «καταλαβαίνουν»
Πέντε εφευρέσεις για να γεφυρωθεί το κενό με την πραγματικότητα Τα μεγάλα γλωσσικά μοντέλα (LLMs) πέτυχαν κάτι εντυπωσιακό: συμπίεσαν τεράστιο μέρος της ανθρώπινης γραπτής γνώσης σε ένα μηχανισμό πρόβλεψης συμβόλων. Όμως η ίδια τους η επιτυχία αναδεικνύει το δομικό τους κενό. Η γλώσσα περιγράφει τον κόσμο, δεν τον ισοδυναμεί. Έτσι, η «κοινή λογική» των LLMs […]

Το AGI δεν είναι προ των πυλών
Γιατί η Γενική Τεχνητή Νοημοσύνη παραμένει μακρινός στόχος Η δημόσια συζήτηση γύρω από την Τεχνητή Νοημοσύνη έχει μετατοπιστεί από τις πρακτικές εφαρμογές των μεγάλων γλωσσικών μοντέλων σε έναν σχεδόν μεταφυσικό ορίζοντα προσδοκιών: την επίτευξη Τεχνητής Γενικής Νοημοσύνης. Η ιδέα ότι τα σημερινά συστήματα παραγωγικής ΤΝ αποτελούν προθάλαμο του AGI έχει διαδοθεί τόσο ευρέως ώστε συχνά […]

Αυτή δεν είναι η Τεχνητή Νοημοσύνη που μας υποσχέθηκαν
Γιατί η αλόγιστη χρήση LLMs στο Δημόσιο είναι επιστημονικά και θεσμικά επισφαλής Η διάλεξη του Michael Wooldridge στη Royal Society έθεσε το ζήτημα στη σωστή του βάση: τα σημερινά Μεγάλα Γλωσσικά Μοντέλα δεν είναι «λογικός νους», αλλά στατιστικοί μηχανισμοί πρόβλεψης ακολουθιών λέξεων. Δεν διαθέτουν την έννοια αλήθειας, δεν έχουν επίγνωση των ορίων τους και δεν […]
Τεχνητή Νοημοσύνη και Δημόσιο Συμφέρον
Τα επιστημονικά επιχειρήματα κατά της αλόγιστης χρήσης ΤΝ στο Δημόσιο Η Τεχνητή Νοημοσύνη προβάλλεται συχνά ως ουδέτερο εργαλείο εκσυγχρονισμού της δημόσιας διοίκησης. Η ρητορική της αποδοτικότητας, της ταχύτητας και της μείωσης κόστους δημιουργεί την εντύπωση ότι η ευρεία υιοθέτησή της αποτελεί αυτονόητη πρόοδο. Ωστόσο, η επιστημονική βιβλιογραφία επισημαίνει ότι η αλόγιστη ενσωμάτωση αλγοριθμικών συστημάτων σε […]

Δημιουργώντας ένα Ανοιχτό Ελληνικό Σώμα Κειμένων από το Openbook.gr
Από το Web Scraping σε ένα Καθαρό Dataset, έτοιμο για έρευνα Στο GlossAPI, η αποστολή μας είναι να δημιουργούμε ανοιχτά, υψηλής ποιότητας ελληνικά σύνολα δεδομένων που υποστηρίζουν το ελληνικό οικοσύστημα Τεχνητής Νοημοσύνης (AI). Σε αυτό το άρθρο, παρουσιάζουμε το τελευταίο μας dataset: μια συλλογή μεγάλης κλίμακας ελληνικών βιβλίων από το Openbook.gr, η οποία επεξεργάστηκε και […]